

I joined the Tribe community about a year ago, but haven't been particularly active. That changed in February, after I attended a Tribe webinar on model evaluation (aka evals). The webinar ended with a call to members who want to get involved with evals to get in touch with Michael (Head of AI Engineering at Tribe). I did so immediately, as getting GenAI systems to behave is one of my favourite GenAI areas – that's what evals are all about.
Michael and I hit it off well and agreed on a "short" trial project, where I would add support for guardrails to the internal Tribe AI platform. He estimated the effort at about a week of full-time work, which I was going to complete over a couple of weeks due to my other client obligations.
As I'm writing this six weeks later, we are putting the final touches on the project. That is, fully supporting guardrails took three times longer than we expected! However, we are all happy with the outcome. This is because guardrail support turned out to be more complicated than anticipated.
I'm sharing this article in the hope of helping others better anticipate the challenges of implementing guardrails. First, I cover general definitions of guardrails and the goals of the internal Tribe AI platform. Then, I provide several examples of the issues we encountered with adding guardrail support. These experiences contain general takeaways, which I summarise at the end of the article.
Defining Guardrails
Guardrails intercept model inputs or outputs to help ensure that the overall system behaves as expected. The most basic guardrail frameworks do this by rejecting certain messages (e.g., filtering out hate speech). More general guardrail frameworks may edit messages rather than only apply rejection criteria (e.g., redact personal information or ensure outputs conform to a specific JSON schema).
GenAI systems need guardrails because the AI models can't be trusted to always behave as expected. Even the most advanced models can be tricked into misbehaving. Guardrails provide a defensive layer that supports safe, reliable, and policy-compliant AI system behaviour. However, since most guardrails are implemented as probabilistic models, they only support getting to the desired behavior. In many real-world scenarios, 100% policy compliance isn't feasible.
As a concrete example, let's say we're building a customer support chatbot. We want our chatbot to stay on topic and only help customers use our product. If we were to rely solely on prompt engineering, we'd be passing the user's query together with our system prompt to the AI model. Then, a conversation may unfold like this:
User: Tell me about alternative products.
Model: Sure! Here are some ways the products of our competitors are superior...
We clearly don't want our customer support chatbot promoting the competition! To stop this, we could add two guardrails: An input guardrail to check user messages and reject those that are off-topic, and an output guardrail to filter out any mentions of competitors. However, this may turn out to be too restrictive, as we'd still want to help customers who are migrating from competing products.
This is where a flexible platform for building our GenAI product would be handy...
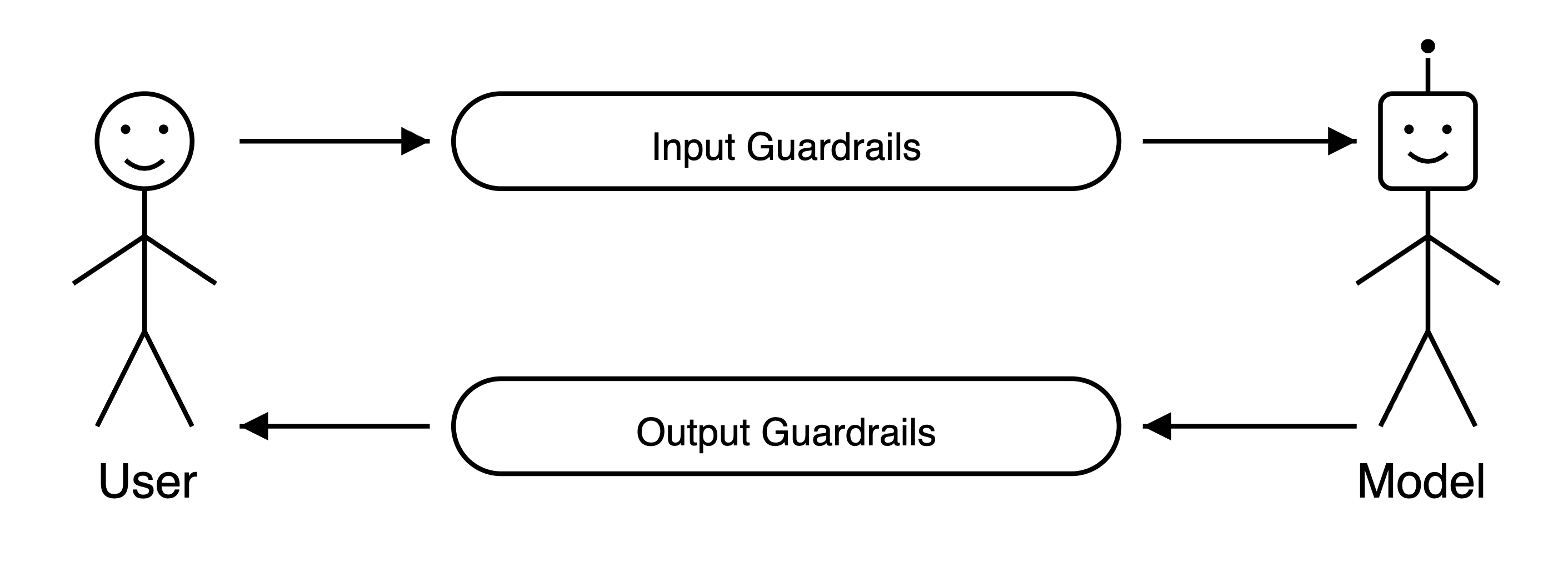
The Tribe AI Platform
While much of the AI buzz is around new model capabilities, realising the value from AI requires deploying systems and products, not just models. Robust production systems typically comprise multiple databases, continuous development and deployment flows, comprehensive automated tests, instrumentation to track how the system is behaving, identity and access management, and more. Such components are deterministic and well-understood, as they've been used in software systems for decades. They are now "boring" technology—typically not buzz-worthy.
The Tribe AI platform makes the creation of full AI systems easier. It provides reusable components and templates for common patterns, while maintaining flexibility for complex enterprise requirements. This allows project teams to start from a robust production-ready base and adapt the platform to specific client needs.
In addition to all the "boring" components noted above, the platform includes a chat front-end, AI model selection, custom agent implementations, and tools such as retrieval-augmented generation and AI-initiated Python code execution. This illustrates a key benefit of the platform: it is rapidly evolving to implement new best practices and emerging patterns from AI engineering. This evolution now includes the guardrail component, which is essential to making the overall system behave more predictably.
Adding Guardrails to the Tribe AI Platform
Now that we've established what guardrails are and where they fit in the Tribe AI platform, let's get into the story of adding guardrail support. As noted, it took longer than expected because we underestimated the complexity of supporting guardrails across all the platform areas.
Onboarding and scoping. Going into the project, I was concerned about the time it'd take me to get productive. This is an issue with any new environment, but my concern was exacerbated by the original tight deadline of two weeks. However, onboarding turned out to be straightforward, as the platform is built to accommodate new developers.
Figuring out the scope of the project wasn't as straightforward. I ended my first day with a long list of questions, such as:
- Do we want guardrails to only reject or flag messages, or should we also support message editing?
- What guardrail providers do we want to support? Examples include AWS Bedrock, Guardrails AI Hub, NVIDIA's NeMo, and Promptfoo.
- How do we want to abstract guardrail providers in a shared interface? For example, would we want to share settings for common checks (like rejecting hate speech), or keep it more general?
- Do we only want to integrate guardrail providers into the shared library of reusable components (an internal Python package), or also into the API layer and the UI (i.e., the full platform)? If it's the latter, which parts of the API do we want to guard?
It turned out that others on the team haven't looked deeply into my questions before, so scoping the project became a collaborative exercise. The key conclusion was to start simple and expand from there.
Implementing the simplest flow with mock guardrails. The importance of starting simple came up in my first call with Michael. We've both seen AI/ML projects fail because teams over-focused on tasks like model optimisation, and neglected to think about the full pipeline until it was too late. Neither of us wanted this to happen here, so we agreed to start by implementing the simplest guardrail flow:
- Create a mock guardrail provider that flags messages based on trigger words (e.g., the word "profanity" is considered hate speech).
- Integrate the mock provider into the common library, creating abstractions that can be extended to accommodate real guardrail providers.
- On the API layer, focus only on the non-streaming "send message to agent" endpoint. Get the endpoint to reject or flag inputs and outputs that trigger the mock provider checks.
- Support end-to-end configuration and testing of the integrated flow.
With this initial scope, I had something I could take to an AI assistant and get a draft of the implementation. After a bit of prompting and refactoring, we had our first end-to-end mock guardrail pipeline working within an extensible framework. It was time to expand the scope and make it truly useful.
Streaming decisions. AI chatbots typically stream their response back to the user, so they don't have to wait for the full message to be available. This is essentially a workaround for the slowness of the underlying LLMs. If you've used the likes of ChatGPT and Claude, you've seen streaming in action.
While streaming is good for the user experience, it complicates the implementation of guardrails. It made us consider these key questions:
- Should we buffer the entire response to apply the guardrails?
- If we don't buffer the entire response, how reliable are the guardrail checks?
- Should we apply guardrail checks mid-stream on partial responses?
- What happens to the already-streamed response if the guardrail check fails?
- Should we introduce latency by pausing the stream while running guardrails?
We decided that buffering the entire response would hurt the user experience too much, as it'd mean no streaming when guardrails are enabled. Instead, we apply guardrails to the already-streamed partial response every N characters, where N is configurable. We leave it up to the API user to redact the part that's been streamed if the message is rejected by the guardrail. To be safe, we also apply the guardrails at the end of the stream. We kept the implementation simple by pausing the stream while running guardrail checks, but checking while streaming is a sensible future optimisation.
Simplifying AWS Bedrock. With all the messaging endpoints protected, it was finally time to add real guardrails. Given the partnership between Tribe and AWS, supporting the guardrails from AWS Bedrock was a natural next step. However, the Tribe AI platform is also used for clients who aren't on AWS, or are on AWS but would rather not use Bedrock for GenAI. Therefore, we needed to abstract and simplify Bedrock's guardrails, making them an option for a guardrail provider, not the guardrail provider.
One key decision we made in supporting Bedrock guardrails was to rely only on the ApplyGuardrail endpoint. We intentionally ignored the option of applying guardrails as part of calls to the Bedrock LLM endpoints to avoid tight coupling to Bedrock. While this may introduce some extra latency, generically supporting multiple model and guardrail providers is an important feature of the Tribe AI platform.
The other key decision was around simplifying the Bedrock guardrail configuration to support rapid experimentation. Similarly to other AWS products, Bedrock guardrails are very flexible, with an API that's designed for future extensions. However, this makes getting familiar with the API a non-trivial exercise, which may not be the top priority for a client project team. With our implementation, platform users can create Bedrock guardrails with a YAML definition like the one below, without needing to fully understand the more elaborate CreateGuardrail endpoint.
namespace: test
name: guardrail_name
description: A test guardrail spec.
topics:
- name: Topic 1
definition: Definition of topic 1
examples:
- Example 1
- Example 2
content_filters:
- type: HATE
input_strength: HIGH
output_strength: MEDIUM
word_policy_config:
words:
- badword1
- badword2
managed_word_lists:
- PROFANITY
sensitive_information_policy_config:
pii_entities:
- EMAIL
- PHONE
regex_patterns:
- 'sensitive_word_prefix\w+'Figure 2: Delightful YAML guardrail config.
Guarding all the things. As I was implementing the core guardrail functionality, more areas worth guarding kept popping up. Following the principle that any LLM input or output is a potential vector for unwanted behavior, we decided to also guard:
- Assets uploaded by the user, such as PDF documents.
- Definitions that come from untrusted sources, like custom agent prompts.
- Agent interactions with tools that have unbounded inputs and outputs, e.g., web search and code execution.
- Non-text assets, such as images and voice chats.
Given that the platform code gets tailored to specific client needs, much of this guarding would be excessive in certain scenarios. Going back to our customer service chatbot, the guardrails needed if it's exposed to end users would be different from the guardrails needed if it's only used internally to help human customer service staff. Therefore, we made it easy to turn the guarding of any area on or off.
Supporting and abstracting more providers. The hard part of the implementation was choosing the right abstractions and ensuring that all the relevant paths are covered. Now we're at a point where it's trivial to add more guardrail providers to supplement or replace the guardrails provided via Bedrock. For example, we may extend the code to add guardrails from Guardrails AI Hub, NVIDIA's NeMo, or Promptfoo. As a simple showcase, I took a couple of hours to implement a guardrail provider that relies on regular expressions. It should be a similarly trivial exercise to implement a more sophisticated provider that uses an LLM with custom instructions to reject specific topics. But with the full guardrail framework in place, it's now time to move on to the next project rather than try to anticipate all the possible guardrail providers that clients may need.
.gif)
Takeaways: Consider This When Implementing Guardrails
When implementing guardrails in your project, consider the following questions and recommendations:
- What risks do you want to guard against? Key categories include generation of unwanted content, discussion of banned topics, handling sensitive information, hallucination reduction, and prompt attacks.
- What's your tolerance level to imperfect guardrails? Remember that achieving 100% protection from a specific risk would require deterministic code rather than a probabilistic classifier.
- What is the simplest scenario you can support? Implement that first.
- What guardrail actions are needed? When adding guardrails to a live system, start with logging the actions that would be taken, and only then turn on rejection, redaction, or user-visible flagging.
- What providers will you use for guardrail checks? Consider relying on pre-configured providers like Bedrock before building your own custom classifiers.
- Where in your systems will you apply guardrails? Pay special attention to API endpoints, ingestion pipelines, and any LLM touchpoints.
- What elements do you want to guard? Consider at least text, audio, documents, images, video, and tool use.
- How much extra latency and cost are you willing to tolerate for each guardrail? For example, there may be risks that'd require delaying streaming responses.
Importantly, no AI can answer all these questions for you. But AI assistants can certainly help you think through the questions, scope the work, and then implement draft solutions. That's exactly how I approached the project as the accountable human.
Beyond Guardrails
While the "one week" trial project took longer than expected, everyone involved was satisfied with the outcome. With guardrails now in place, I'm going to help Tribe implement other parts of the platform. As I'm still interested in getting AI to behave, the next project may be around evals. Please stay tuned for future posts on our learnings.
If you have any questions about this article, please get in touch as I'm always happy to chat about these topics. And if you want to avoid the challenges of implementing guardrails and quickly see value from AI in your company with the Tribe AI platform, please use the expression of interest form.

.webp)








