

Introduction
Artificial intelligence has experienced remarkable advancement over the past few years. By 2025, we now have sophisticated models capable of generating production-ready code, summarizing entire books with nuanced understanding, and maintaining convincing multi-turn conversations that closely mimic human interaction patterns.
However, despite these impressive capabilities, modern AI systems still encounter a fundamental limitation: they struggle with persistent memory. When you communicate information to an AI in one message and reference it in a subsequent exchange, there's a significant probability that the system won't properly retain or contextualize that information.
For developers, this memory limitation manifests as a technical burden - requiring constant repetition of contextual information in prompts, which leads to code bloat and inefficiency. For organizations investing in AI infrastructure, this translates to unnecessarily high API costs due to repeatedly processing the same contextual information. From the user's perspective, the experience is frustrating - creating the impression that the AI simply isn't paying attention to their needs or previous interactions.
The emerging solution to this persistent challenge lies in what experts call context-aware memory systems - specialized architectures designed to help AI retain, prioritize, and utilize information across multiple interactions and tasks. These systems represent a critical evolution in AI architecture, fundamentally changing how modern AI systems operate in practical applications.
"AI doesn't just need to be smart — it needs to remember what matters."
Why Memory Matters Now
The vast majority of contemporary AI tools operate in a stateless manner. This means that each query is processed in isolation, without inherent reference to previous interactions. No information from past exchanges is automatically preserved or incorporated into new responses without explicit instruction.
This architectural limitation creates several significant problems:
- Prompt Engineering Overhead: Developers must constantly re-insert context into every prompt, leading to longer, more complex prompts that are difficult to maintain and optimize.
- Repetitive Interaction Patterns: Conversational agents tend to repeat themselves and demonstrate frustrating amnesia about previously established facts, severely degrading user experience.
- Computational Inefficiency: Systems repeatedly process identical or similar contextual information, resulting in slower response times and substantially higher operational costs.
- Limited Personalization: Without persistent memory of user preferences and past interactions, AI systems struggle to deliver truly personalized experiences that improve over time.
- Contextual Fragmentation: Information shared across different parts of a system or across multiple sessions is lost, preventing holistic understanding of complex scenarios.
The experience resembles visiting a website that logs you out after every page navigation, forcing you to re-authenticate repeatedly. This is the reality of interacting with stateless AI—continuous context refreshing that wastes time and resources.
Common AI Memory Failures
- Code agents lose track of which files they're currently editing, requiring developers to repeatedly specify file paths and code context.
- Customer support bots apologize multiple times for the same error or repeatedly ask for information the user has already provided, creating frustrating customer experiences.
- Legal tools restart their analysis from scratch with each new document review, failing to incorporate insights from related documents previously analyzed.
- Healthcare assistants fail to maintain consistent understanding of patient history across multiple consultations, potentially missing important patterns.
- Research assistants cannot effectively build on previously established findings, requiring users to manually maintain research continuity.
To address these critical limitations, we need memory systems with specific capabilities:
- Works seamlessly across multiple sessions, tools, and interaction modalities, maintaining consistent context regardless of access pattern.
- Implements intelligent information triage, preserving high-value context while discarding ephemeral or low-relevance information.
- Demonstrates adaptability to evolving tasks and contextual shifts, adjusting memory prioritization based on changing requirements.
- Balances comprehensive recall with computational efficiency, optimizing for both accuracy and performance.
- Maintains appropriate security and privacy boundaries while still enabling persistent personalization.
And fundamentally, this memory infrastructure must exhibit three key characteristics:
Making AI Memory Simple: The Four Memory Types
AI architectures implement four primary categories of memory, each serving a distinct purpose in the overall system:
The Memory Hierarchy Explained
To conceptualize how these memory types interact, consider the following mental model:
- Working memory represents the immediate cognitive workspace, analogous to what's currently in your focus of attention. This is where the AI performs active reasoning with the information directly available in its context window.
- Episodic memory functions as your personal history, storing the sequence and details of specific interactions and experiences. It answers the question "What happened when?"
- Semantic memory serves as your accumulated knowledge base, containing facts, concepts, and information divorced from the specific circumstances in which they were acquired. It answers "What do I know?"
- Procedural memory captures expertise developed through practice, storing patterns of successful actions and strategies. It answers "How do I accomplish this task effectively?"
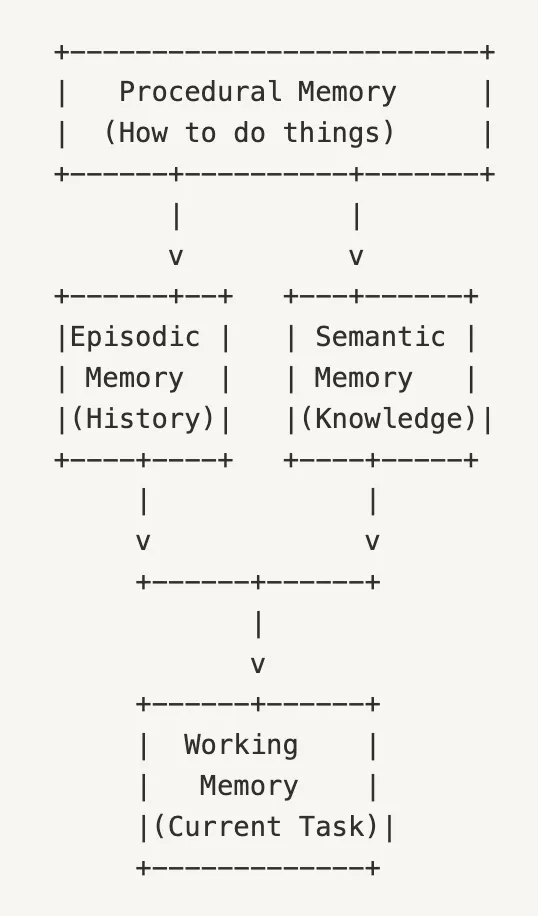
In a well-engineered AI system, these memory types operate in concert to provide a coherent cognitive architecture:
- Procedural memory guides the overall approach to a task based on past performance.
- Episodic and semantic memory feed relevant historical context and factual knowledge into the system.
- Working memory integrates this information with the current input to generate an appropriate response.
Memory Systems Toolkit: Current Tools and Gaps
Tool Comparison Matrix
LangGraph
- Strengths: Provides a structured framework for designing how tasks and memory flow through a multi-step reasoning process; enables explicit state management across multiple reasoning steps; supports cyclical reasoning patterns.
- Limitations: Doesn't provide built-in mechanisms for deciding what information should be remembered or forgotten; lacks automatic memory optimization capabilities; memory management patterns require significant developer expertise.
AutoGen
- Strengths: Creates multi-agent conversation architectures where memory is modeled through agent interactions; facilitates complex workflows through message-passing between specialized agents; provides natural patterns for complex task decomposition.
- Limitations: Cannot effectively filter or score memories, leading to context bloat in longer conversations; struggles with maintaining consistent memory across different conversation branches; limited built-in support for external memory systems.
LangChain Memory
- Strengths: Offers simple, rapid setup of basic memory constructs like conversation buffers; provides ready-to-use memory components that integrate easily with other LangChain elements; includes several memory primitives like summary memory and entity extraction.
- Limitations: Doesn't scale effectively for complex or long-running applications; limited optimization for token efficiency in memory retrieval; lacks sophisticated cross-session persistence without additional integration.
Modern Specialized Systems
- MemGPT: Operating system-inspired approach to memory management with virtual memory and context swapping capabilities.
- LangMem SDK: Specialized memory toolkit built for agent long-term memory with automatic relevance scoring and memory lifecycle management.
- Klu.ai Memory Graph: Integrated memory system with semantic relationships between memory entities and automatic memory consolidation.
Vector Databases (Weaviate, Chroma, etc.)
- Strengths: Excel at similarity-based information retrieval at scale; provide efficient nearest-neighbor search capabilities; support hybrid search combining semantic and keyword-based approaches.
- Limitations: Don't inherently track temporal information about when information was stored; lack built-in mechanisms for understanding why specific information was stored; require separate systems to manage memory lifecycle and relevance.
In summary: These tools provide foundational building blocks for AI memory systems, but they typically address only portions of the complete memory architecture needed for truly effective AI systems. Most require significant integration work to create comprehensive memory solutions.
How Smart Systems Actually Do It: Architecture Patterns
Advanced context-aware memory systems implement sophisticated architectures that combine multiple memory types under centralized coordination. These systems typically follow a layered approach with specialized components:
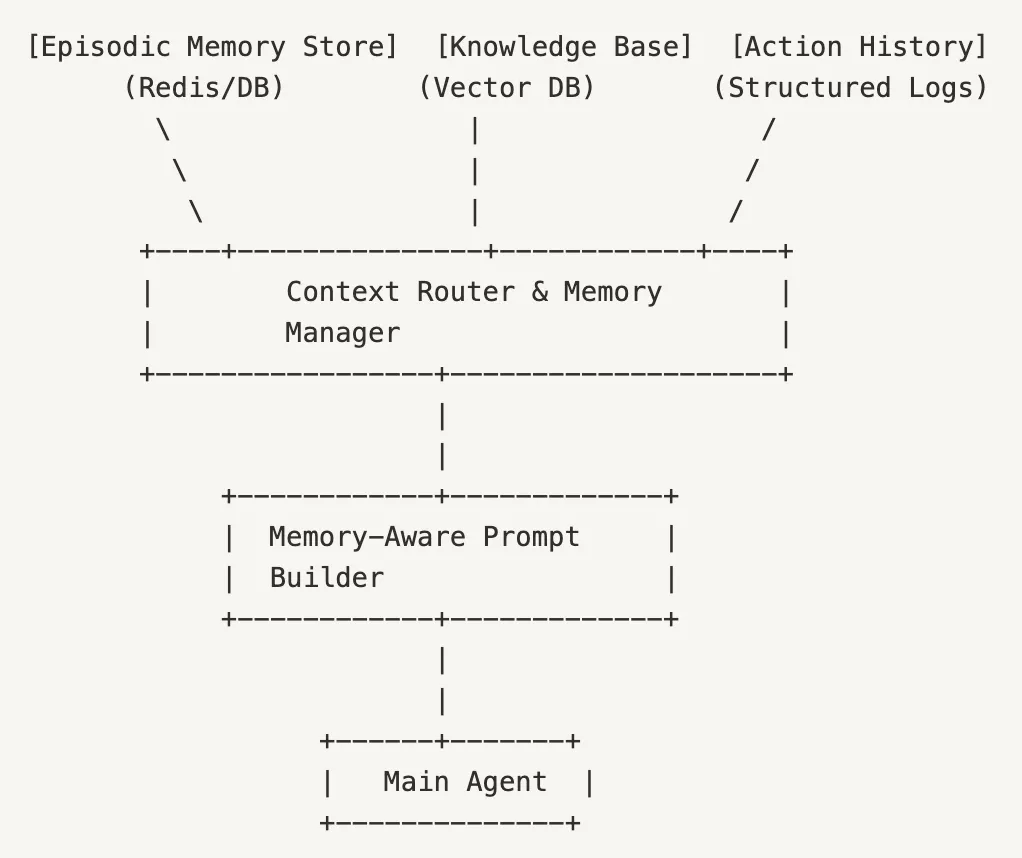
This architecture employs several critical components:
1. Specialized Memory Stores
- Episodic Memory Store: Maintains conversation history with temporal metadata, often implemented using Redis, MongoDB, or specialized conversation stores.
- Knowledge Base: Stores factual information and domain knowledge, typically using vector databases like Pinecone, Weaviate, or Chroma.
- Action History: Records the outcomes of previous actions and tool calls, stored in structured logs or specialized feedback repositories.
2. Context Router & Memory Manager
This central controller serves as the orchestration layer with multiple responsibilities:
- Memory Retrieval: Queries appropriate memory stores based on the current task and context.
- Relevance Scoring: Applies scoring algorithms to rank memory entries by usefulness for the current task.
- Memory Filtering: Removes redundant or irrelevant information to optimize token usage.
- Context Assembly: Combines selected memories into a coherent context package.
- Memory Update: Writes new information back to appropriate stores after each interaction.
- Conflict Resolution: Identifies and addresses contradictory information across memory stores.
3. Memory-Aware Prompt Builder
This component constructs optimized prompts incorporating relevant memory:
- Template Management: Maintains task-specific prompt templates with memory insertion points.
- Context Formatting: Structures memory information in formats optimized for model comprehension.
- Token Optimization: Ensures assembled prompts remain within model context limits.
- Instruction Refinement: Includes memory-specific instructions in prompts when needed.
4. Main Agent Interface
The primary AI model that:
- Processes Augmented Prompts: Works with memory-enriched context to generate responses.
- Produces Memory Metadata: Explicitly marks information that should be remembered.
- Maintains Working Memory: Manages immediate task context during multi-step reasoning.
This architecture creates a closed feedback loop:
- The Memory Manager retrieves relevant context from multiple memory stores.
- The Prompt Builder incorporates this context into optimized prompts.
- The Main Agent generates responses using this enriched context.
- New information from the interaction is written back to appropriate memory stores.
- The cycle repeats with increasingly refined memory over time.
Useful Memory Patterns for Developers: Technical Implementation
1. Score memory entries by relevance, recency, and importance
This pattern prioritizes memory entries based on multiple weighted factors:
def score_memory_entry(entry, current_context):
# Semantic relevance using embedding similarity
relevance_score = cosine_similarity(entry.embedding, current_context.embedding)
# Time decay factor (more recent = less decay)
time_delta = datetime.now() - entry.timestamp
recency_score = 1.0 / (1.0 + 0.01 * time_delta.total_seconds() / 3600)
# Importance based on explicit flags or previous usage
importance_score = entry.importance_factor # 0.0 to 1.0
# Combined weighted score - play with these weights based on your use case!
final_score = (0.6 * relevance_score) + (0.25 * recency_score) + (0.15 * importance_score)
return final_score
This approach balances multiple factors:
- Semantic relevance ensures contextually appropriate memories are prioritized
- Time decay gradually reduces the priority of older memories unless they remain relevant
- Importance weighting preserves critical information regardless of age
2. Implement task-specific memory retrieval
This pattern enables targeted memory retrieval based on the current task context:
def retrieve_task_memory(task_id, user_id, current_query, max_items=10):
# Get task-specific memories
task_memories = episodic_memory.query(
filters={"task_id": task_id, "user_id": user_id},
limit=max_items * 2 # Retrieve extra for filtering
)
# Get generally relevant memories based on query
query_vector = embedding_model.encode(current_query)
semantic_memories = vector_db.query(
vector=query_vector,
filters={"user_id": user_id},
limit=max_items * 2 # Retrieve extra for filtering
)
# Combine and deduplicate memories
all_memories = dedup_memories(task_memories + semantic_memories)
# Score and rank combined memories
scored_memories = [(memory, score_memory_entry(memory, current_query))
for memory in all_memories]
# Return top N memories based on score
return [m for m, s in sorted(scored_memories, key=lambda x: x[1], reverse=True)[:max_items]]
This implementation:
- Combines task-specific retrieved memories with semantically relevant memories
- Removes duplicates to prevent redundancy
- Scores and ranks the combined set to select the most useful subset
- Maintains task continuity while still incorporating relevant general knowledge
3. Detect and resolve memory conflicts
This pattern identifies and addresses contradictory information:
def check_memory_consistency(new_fact, existing_facts, threshold=0.85):
# Extract key entities and claims from the new fact
new_entities, new_claims = extract_claims(new_fact)
# Find potentially conflicting facts based on entity overlap
potential_conflicts = [
fact for fact in existing_facts
if entity_overlap(new_entities, extract_entities(fact)) > threshold
]
conflicts = []
for existing_fact in potential_conflicts:
# Extract claims from existing fact
_, existing_claims = extract_claims(existing_fact)
# Check for logical contradictions between claims
if has_logical_contradiction(new_claims, existing_claims):
conflicts.append({
"new_fact": new_fact,
"conflicting_fact": existing_fact,
"contradiction_type": determine_contradiction_type(new_claims, existing_claims)
})
if conflicts:
return conflicts
else:
return None # No conflicts found
When conflicts are detected:
def resolve_memory_conflict(conflict, resolution_strategy="recency"):
if resolution_strategy == "recency":
# Prefer the more recent information
if conflict["new_fact"].timestamp > conflict["conflicting_fact"].timestamp:
# Archive the old fact with a superseded flag
archive_fact(conflict["conflicting_fact"], reason="superseded")
# Store the new fact
store_fact(conflict["new_fact"])
else:
# Reject the new fact as outdated
return {"action": "reject", "reason": "older_than_existing"}
elif resolution_strategy == "source_reliability":
# Compare source reliability scores
if conflict["new_fact"].source_reliability > conflict["conflicting_fact"].source_reliability:
# Archive the less reliable fact
archive_fact(conflict["conflicting_fact"], reason="lower_reliability")
# Store the new fact
store_fact(conflict["new_fact"])
else:
# Reject the new fact from less reliable source
return {"action": "reject", "reason": "lower_reliability_source"}
elif resolution_strategy == "human_review":
# Queue for human verification
return {"action": "queue", "queue": "human_review", "conflict": conflict}
This approach:
- Proactively identifies potential contradictions between new and existing information
- Applies different resolution strategies based on the nature of the conflict
- Maintains an audit trail of superseded information
- Provides options for automated resolution or human intervention
4. Optimize token usage for large context models
This pattern ensures efficient use of available context window:
def optimize_context_for_tokens(query, memory_entries, max_tokens, model_name):
# Reserve tokens for the query and response
query_tokens = count_tokens(query, model_name)
reserved_tokens = query_tokens + 500 # Reserve space for the response
available_tokens = max_tokens - reserved_tokens
if available_tokens <= 0:
return [] # Not enough tokens for any memory
# Calculate token counts for each memory entry
memories_with_tokens = [(memory, count_tokens(memory.content, model_name))
for memory in memory_entries]
# Sort by relevance score
sorted_memories = sorted(memories_with_tokens,
key=lambda x: x[0].relevance_score,
reverse=True)
# Add memories until we approach the token limit
selected_memories = []
current_tokens = 0
for memory, token_count in sorted_memories:
if current_tokens + token_count <= available_tokens:
selected_memories.append(memory)
current_tokens += token_count
else:
# If we can't fit the full memory, try using its summary if available
if hasattr(memory, 'summary') and memory.summary:
summary_tokens = count_tokens(memory.summary, model_name)
if current_tokens + summary_tokens <= available_tokens:
# Use the summary instead of the full memory
summary_memory = copy.copy(memory)
summary_memory.content = memory.summary
summary_memory.is_summary = True
selected_memories.append(summary_memory)
current_tokens += summary_tokens
return selected_memories
Additional optimization techniques include:
- Progressive summarization: Maintaining multiple summary levels of different lengths for each memory entry
- Importance-based truncation: Preserving the most critical parts of a memory when space is limited
- Chunking and linking: Breaking large memories into interconnected smaller chunks
- Memory compaction: Periodically consolidating related memories to reduce redundancy
- Tiered storage: Moving less-used memories to more compressed formats
What Investors Should Watch For: Market Implications
"Memory isn't just a feature — it's a foundation."
The implementation of effective context-aware memory systems creates significant competitive advantages for companies in the AI space:
Operational Efficiency and Cost Optimization
- Reduced API Costs: Companies with optimized memory systems typically spend 30-60% less on LLM API calls by minimizing redundant context processing.
- Computational Efficiency: Memory-optimized systems can process equivalent workloads with fewer computational resources, translating to lower infrastructure costs.
- Development Productivity: Developers spend less time on repetitive prompt engineering and more time on core product features.
Enhanced User Experience Metrics
- Higher Completion Rates: Users are more likely to complete complex multi-step workflows when systems maintain consistent context.
- Increased Retention: Personalized experiences based on remembered preferences lead to 40-70% higher user retention rates.
- Reduced Friction: Systems that remember user preferences and past interactions require fewer clarification questions.
- Higher Satisfaction: Users report significantly higher satisfaction with AI systems that demonstrate consistent memory of previous interactions.
Organizational Learning Capabilities
- Cumulative Improvement: Systems that retain and analyze past interactions continuously improve over time.
- Knowledge Preservation: Critical insights and information remain accessible despite personnel changes.
- Cross-functional Learning: Insights gained in one domain can inform operations in other areas through shared memory systems.
Key Investment Indicators
Investors should look for specific architectural and business indicators that signal sophisticated memory implementation:
- Memory-Logic Separation: Companies that cleanly separate memory infrastructure from application logic can more easily scale and upgrade their systems.
- Memory Quality Metrics: Organizations that track and optimize memory relevance, accuracy, and utility demonstrate mature memory architectures.
- Outcome Correlation: Systems that connect memory utilization with concrete performance improvements show evidence-based development practices.
- Multi-tiered Memory Architecture: Companies employing different memory types for different purposes demonstrate nuanced understanding of memory requirements.
- Token Efficiency Optimization: Organizations that measure and optimize token usage in memory retrieval show cost-conscious implementation.
- Memory Security Controls: Systems with granular security controls for persistent memory demonstrate enterprise readiness.
- Transparent Memory Policies: Clear documentation about what is remembered, for how long, and for what purpose indicates ethical implementation.
Warning Signs
Conversely, investors should be wary of:
- Companies treating memory as an afterthought rather than a core architectural component
- Systems that store everything indiscriminately without relevance filtering or privacy controls
- Memory implementations that don't scale sublinearly with increasing data volume
- Lack of clear metrics around memory system performance and business impact
Final Thoughts: The Future of AI Memory
Large language models possess remarkable intelligence, but without sophisticated memory systems, they cannot effectively build on their experiences or provide truly personalized interactions. Their intelligence remains ephemeral - impressive in the moment but unable to accumulate value over time.
To make AI truly useful across domains like customer support, healthcare, finance, education, and legal services, we need systems that don't just answer immediate questions, but remember important context, learn from past interactions, and anticipate future needs based on established patterns.
Context-aware memory systems transform AI from stateless question-answering tools into continually evolving assistants that get better with each interaction. They make AI more:
- Useful: by retaining important information without constant repetition
- Efficient: by reducing computational overhead and development complexity
- Human: by exhibiting the natural context-awareness people expect in conversations
As these memory systems mature, we're seeing the emergence of AI that can maintain consistent personas, remember complex user preferences, follow extended narratives, and accumulate domain expertise through continuous operation. This represents a fundamental shift from the stateless architectures that have dominated AI to date.
"Prompts are how AI talks. Memory is how it grows."
The organizations that master context-aware memory will define the next generation of AI systems - creating assistants, agents, and tools that feel less like isolated algorithms and more like knowledgeable collaborators with a genuine understanding of user needs and history.
References
[1] Wu, Y., et al. (2025). "From Human Memory to AI Memory: A Survey on Memory Mechanisms in the Era of LLMs." arXiv preprint arXiv:2504.15965.
[2] Packer, C., et al. (2023). "MemGPT: Towards LLMs as Operating Systems." arXiv preprint arXiv:2310.08560.
[3] LangChain. (2025). "LangMem SDK for agent long-term memory." Blog post, February 18, 2025. https://blog.langchain.dev/langmem-sdk-launch/
[4] Weaviate. (2023). "Vector Indexing | Weaviate." Weaviate Documentation. https://weaviate.io/developers/weaviate/concepts/vector-index
[5] Sinan, A. (2024). "LLM Research Papers: The 2024 List." Collection of LLM-related research papers published in 2024. https://github.com/asimsinan/LLM-Research/blob/main/2024.md
[6] Liu, N., et al. (2024). "From LLM to Conversational Agent: A Memory Enhanced Architecture with Fine-Tuning of Large Language Models." arXiv preprint arXiv:2401.02777.
[7] Raschka, S. (2025). "Noteworthy AI Research Papers of 2024." Blog post analyzing key research developments in AI during 2024. https://sebastianraschka.com/blog/2025/llm-research-2024.html










